The expactation-maximization algorithm is a technique to fit a variety of mixture models such as Gaussian mixture. I'll walk through the key idea and why it works.
Problem
Suppose that you have a set of data samples, each of which is sampled from one of the probability distributions. You know the functional form of the distributions. The task is to identify the parameter values as well as which distribution each data sample is generated from.
Overview of the EM algorithm
Let be the probability density function for the th distribution. Given a data sample , the probability that is generated from the th distribution is given by the posterior distribution, i.e.,
Probability is the probability that comes from the th distribution. We can then update the parameters of with the weighted average of the gradients
Once we update , we effectively update since it is parameterized by . Thus, we repeat the calculation again. We repeat the rounds of the caluclations until is convered.
Why it works?
The log-likelihood of the EM algorithm is given by
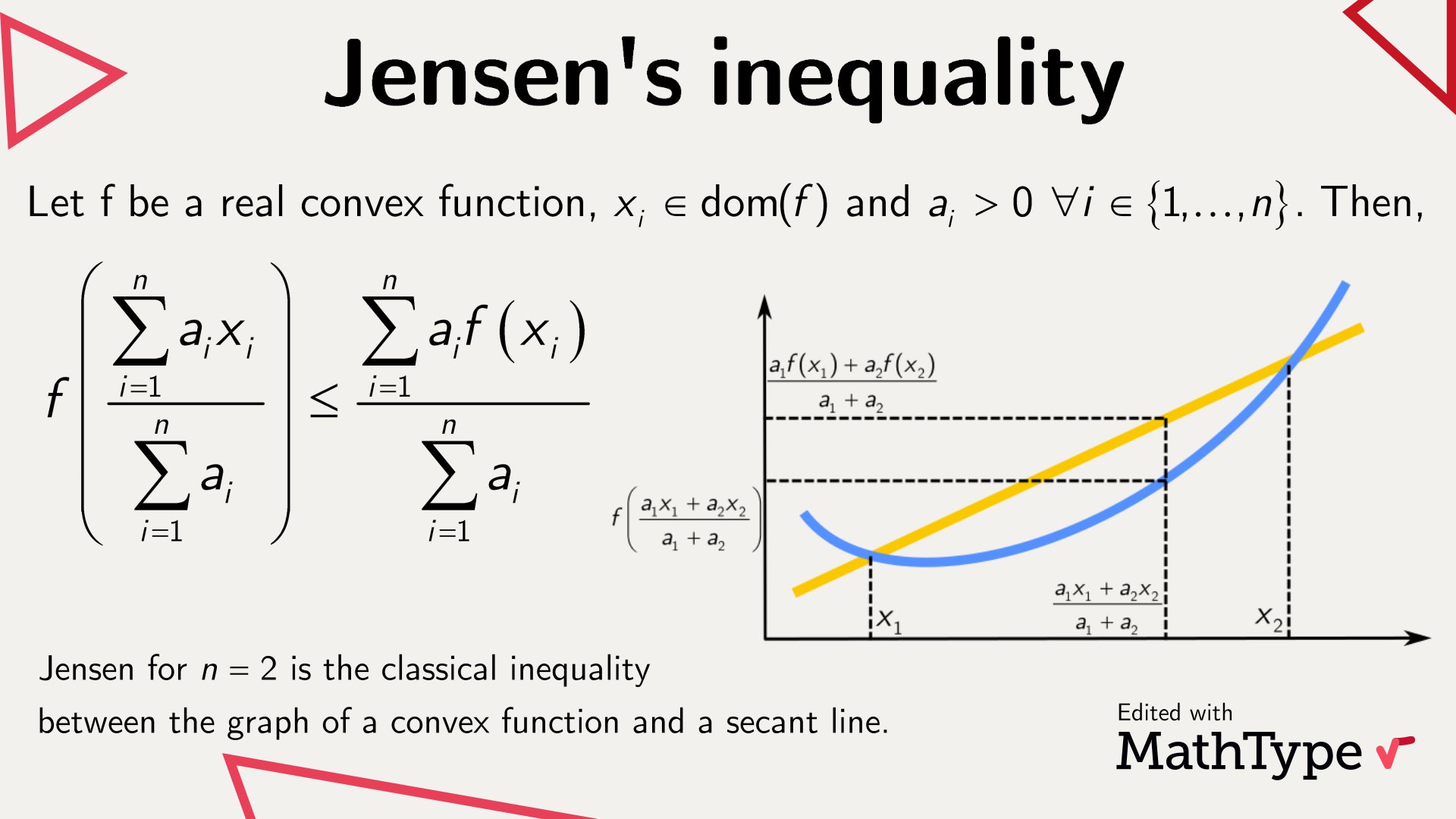
The objective involves which prevents us to derive the analytical form of the gradient with respect to . So, we approximate into another function that is convinient to optimize. One such can be obtained by using Jensen's inequality, which transforms to , i.e.,
if is a concave function. The intuition behind this is that secant line of a convex function lieves above its function.
To apply the Jasen's inequality, we introduce an auxiliary variable that sums to one over , i.e., for all . Without changing , we introduce to by
Let's apply the Jasen's inequality to :
Now, you see that the log of a sum becoems a sum of logs. Also that is the lower bound of so that increasing would increase . The equality holds if is constant, which leads to given by
Maximizing is a constrained maximization problem. We transform the constrained to unconstrained by using Lagrangian, i.e.,
By taking the derivative with respect to and , we have