Rethinking training algorithms for ML
updated: 2022-09-23
#machine-learning/stochastic-gradient-descent
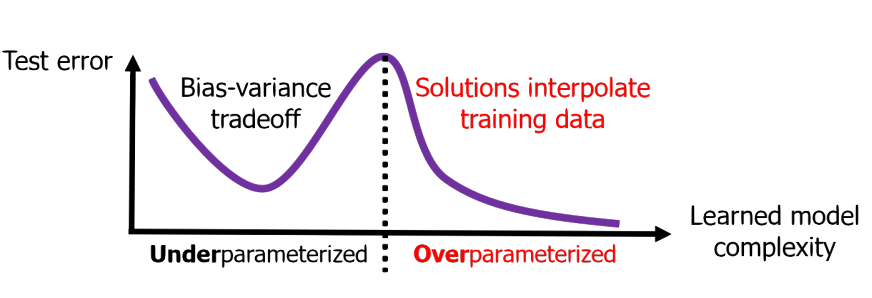
A classical bias-variance tradeoff tells us that as the model complexity increases, the model fits better to training data and less to unseen data. This narrative does not explain recent success in large-scale overparameterized neural networks with billions of parameters. Why do seemingly overparameterized models perform so better without being overfitted to training data? One of the secrets is the training algorithm.
Implicit regularization
A widespread training algorithm for neural networks is stochastic gradient descent algorithm, or SGD. SGD picks a random subset of training data, called batch, and calculate the gradient of parameters based on the batch. The stochastic comes from the fact that the stochastic nature of the gradient as it is calculated from a random sample of data. This stochasticity in gradient prevents overfitting.
- Notes on the Origin of Implicit Regularization in SGD
- On the Origin of Implicit Regularization in Stochastic Gradient Descent - YouTube
- Implicit Gradient Regularization
- Implicit Regularization in Deep Matrix Factorization
- The Implicit Regularization of Stochastic Gradient Flow for Least Squares
Double desent
Overparameterized models + SGD generates a pecuilar phenomena called double descent. Bias-variance trade-off predicts that, as the trainining progresses, a overparameterized model fits better to both training and test data (the first descent). At some point, however, the model fits worse to the test data because it fits too much to the training data, and thus, increases test error. If we continue training the model, the test error eventually descents again.
Superposition
- [Toy Models of Superposition](https://transformer-circuits.pub/2022/toy_model/index.html
Relation to spectral methods
Provable Guarantees for Self-Supervised Deep Learning with Spectral Contrastive Loss